摘要:
云计算在被越来越多的个人和企业所采用, 但人们对于云计算服务在安全性, 可靠性和服务响应确定性方面的担忧也与日俱增. 虽然云服务提供商(Clouds Service Provider) 通常都会承诺SLA(Service Level Agreement)的可用性(Availability)范围等, 但许多云租户不理解可用性的内在复杂性, 因此在选择云平台时缺乏对风险进行评估的能力. 本文首次系统的定义和分析了云计算可用性的算法模型, 特别是对云计算的IaaS, PaaS和SaaS各个层次可用性的内在关系展开定性讨论. 文章的最后, 针对2008年到2012年以来AWS被外界所报道过的服务事故做了相应的统计调查和一些定量分析.
1. 云计算的挑战:
云服务在被越来越多的企业所采用. 据Gartner预测, 2013年公有云的市场份额将会以8%的增长率从2012年的1110亿美金增长至1310亿美金, 如图1所示.

图1 公有云服务市场和年增长率
在IaaS(Infrastructure as a Service)方面, 增长速度为47.3%, 市场份额为90亿美金. 2012年, IaaS增长了42.4%. 2016年, 公有云的市场大小会达到2100亿美金, 增长率为17.7%, 而在IaaS方面会保持41.3%的增长率[1].
然而, 随着大量中小型企业的CIO在考虑把公司的数据和应用迁移到云计算平台上, 伴随而来的是对云计算的服务质量(Quality of Service)的担忧.
UCBerkeley计算机系RAD实验室的Michael Armbrust等在2009年2月发表了关于对云计算服务的论文--“Above the Clouds:A Berkeley View of Cloud Computing”. 文中Berkeley提出了其理解的云计算概念模型, 并提出了云服务必须克服的10大障碍[2], 如图2所示.

图2 Berkeley的云计算模型
在这10大障碍中, 1(Availability of Service), 2(Data Confidentiality and Auditability), 5(Performance Unpredictability), 6(Scalable Storage), 7(Bugs in Large-Scale Distributed Systems), 8(Scaling Quickly) 都与云计算质量紧密相关. Berkeley在对可用性(Availability)的解释中, 还特别提到了DDoS攻击对云计算带来的危害和需要防范的措施.
另外, 据来自Newvem的调查数据报告, 有35%的亚马逊的AWS用户对宕机基本上没有防范措施; 40%的AWS用户没有定期做数据的备份. TeamQuest最近对许多企业的CIO做了一次调查, 接受调查的的CIO有40%的表示他们在使用云计算的时候发生了机群宕机现象[3].
2012年, 许多著名的公有云计算数据中心都发生了重大的安全事故.下面是一些典型的案例[4][5]:
*2012年2月29日和7月26日, 微软的Azure发生事故, 时间分别为长达9个小时和2.5个小时, 许多北美和欧洲的用户无法正常管理和使用其公司正常业务, 有的彻底丢失了他们最新的数据.
* 2012年6月14日, 6月29日, 10月22日和圣诞节期间的12月24日, 亚马逊AWS发生了严重云服务缓慢和崩溃无法访问的问题, 影响的租户包括许多重要的互联网公司, 例如Netflix, pInterest, twitter, Instagram等等[4]. 每次事故导致用户无法正常使用服务的时间长达9个小时和更多.
* 2012年7月10日, 著名的SaaS(Service as a Service)公司Salesforce的服务出现重大停顿. 其原因是提供Salesforce公司IaaS服务的公司(Equinix)的数据中心电源失效. Equinix据说在1分钟内就恢复了电源. 但Salesforce花费了接近9个小时来完整的恢复其相关业务.
* 2012年9月10日, 著名的DNS服务提供商GoDaddy的数据中心服务暂停. GoDaddy管理着接近5千万个域名和5百万个WEB站点. 这次服务无法正常使用长达7个小时. 其原因被解释为路由器的数据被破坏. 也有媒体报道是GoDaddy遭遇到了强大的DDoS攻击. 但这一声称被GoDaddy否认.
* 2012年10月26日, 谷歌的App Engine云服务出现暂停, 时间长达4个小时. 事后谷歌没有发表具体原因解释.
* 2012年10月26日, 著名的云存储提供商Dropbox的服务出现暂停, 时间长达10个小时. 其具体原因不详.
由上可见, 伴随着云计算本身具备的无可争议的巨大价值, 云计算带来的诸多服务质量问题也正变得越来越明显.
因此对云计算的可用性的定性和定量分析逐渐变为一个兼有研究和工程价值的问题. 有助于帮助CIO们评估一个云计算平台.
目前学术和工业界对云计算, 特别是公有云的可用性方面还没有引起足够的重视. 缺乏这方面的定性和定量分析工作.
本文首次系统的定义和分析了云计算可用性的算法模型, 特别是对云计算的IaaS, PaaS和SaaS各个层次可用性的内在关系展开定性讨论. 文章的最后, 针对2008年到2012年以来AWS被外界所报道过的服务事故做了相应的统计调查和一些定量分析.
2. 云计算可用性(Cloud Computing Availability)
云计算可用性是一个很广义的概念. 本文定义云计算可用性如下:
云计算可用性: 包括IaaS, PaaS和SaaS各个层面服务的连接, 可靠性, 延时, 数据泄露和丢失, 网络攻击以及其他任何意外而导致租户的业务不能满足期望, 或者更严重的业务完全暂停. 云服务商通常是通过SLA(Service Level Agreement) 来量化可用性的承诺, 给出相应的Availability的数值范围, 例如,99.9%或者99.99等等.
按照云计算层次的分类[6], 我们认为云计算的Availability(简称AvailabilityCS) 包括IaaS的Availability(AvailabilityIaaS), PaaS的Availability(AvailabilityPaaS)和SaaS的Availability (AvailabilitySaaS).

我们认为, 用户最终感知的的云计算的可用性是与云计算3个层面的可用性紧密相关的.
在下面小节中, 我们首先来形式化定义一个云计算服务的可用性并做相应的算法讨论. 然后, 对云计算分层模型中IaaS, PaaS和SaaS在可用性之间的关系做理论探讨.
2.1 可用性
假定在一个采样时间范围(例如时间 T小时内)服务发生的不可用(Unavailable)次数是N. 每次不可用之前正常运行的时间定义为TBFi(Time Before Failure). 每次用来恢复服务正常运行的时间定义为TTRi(Time To Repair).
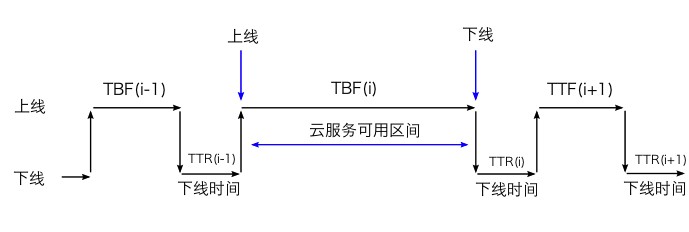
图3 云计算服务的可用性
由图3可知, 在采样时间T范围内, 服务的可用性为:

因此, 我们推导出在时间T小时里, 云服务的可用性为:

其中:
MTBFT: 在时间T内, 云服务的Mean Time Before Failure[7].
MTTRT: 在时间T内, 云服务的Mean Time To Repair[8].
根据公式1, 我们可以定义一个云服务在基于采样周期T下, 时间跨度为K下的Mean Time Availability(MTA)为:

假设一个云服务的SLA取样时间T是每天, 或者说24个小时. 如果考察7224个小时的MTA, 根据上述公式, 其MTA计算方法为:




