
对医疗数据数字化及数据共享的标准化和倡导,改进并降低数据存储成本,并能够在商业硬件上运行,这些都促成了大数据在医疗行业的应用,并以更低的成本获得更好的医疗卫生服务为目标。
应用 大数据 的动力何在
医疗卫生成本拉动了对以 大数据 为驱动的医疗卫生方面的应用需求。在过去的几十年里,美国的医疗卫生支出已经超过了GDP增量,并且超过了任何一个其他发达国家的医疗支出。据经济合作与发展组织(OECD)称,尽管支出很高,但如果以便利性、平等性、质量、效率以及健康人数为指标的话,美国的医疗卫生系统在了11个国家中排名最后(如下图所示)。对医疗数据数字化及数据共享的标准化和倡导,改进并降低数据存储成本,并能够在商业硬件上运行,这些都促成了 大数据 在医疗行业的应用,并以更低的成本获得更好的医疗卫生服务为目标。

以价值为准的医疗卫生
“平价医疗卫生法案”的一个目标是通过医疗信息技术的有效利用来改进医疗卫生,从而达到以下目的:
▪ 提高医疗卫生的质量和协调能力,使成果与现有的专业知识一致。
▪ 缩减医疗卫生支出,减少可避免的过度使用。
▪ 已改革的支付系统提供支持。

医疗保险公司、老年卫生医疗制度(美国政府向65岁以上的人提供医疗保险)、医疗补助制度(美国政府向贫困者提供医疗保险)正在从收取服务性费用转向以价值为基础、数据为驱动的激励转变。这种激励模式鼓励高质量、高性价比的医疗服务,并且还能展示对电子医疗记录的有效利用。

医疗卫生数据
医疗卫生行业的数据80%都是非结构化数据,并且数据量还在呈指数式增长。对于这些非结构化数据的获取,比如医疗设备检测结果、医生的记录、实验结果、影像学报告、医用函件、临床数据和财务数据等,是改善病患医疗服务及提高效率的无价资源。
以下是未来可以受益于大数据分析的医疗卫生数据源的例子:
▪ 索赔报告:是医疗卫生服务供应商向保险公司提交的文件以获得保险赔偿。《健康保险隐私及责任法》(Health Insurance Portability and Accountability Act,缩写为HIPAA)中最关键的一个要素就是通过鼓励在医疗服务供应商和保险公司之间广泛使用电子文档交换(Electronic Document Interchange,缩写为EDI),建立电子医疗记录方面的国家级行业标准来提高效率。索赔报告交换包括国际疾病分类(International Classification of Diseases,缩写为ICD)诊断码, 治疗方案、日期、供应商ID以及花费金额。
▪ 电子健康/医疗记录数据(Electronic Health/Medical Record, 缩写为 EHR或者EMR): 医疗电子记录激励体系在建立之时便是用来鼓励职业人员以及医院采用并展示对已认证的EHR技术的有效应用。EHR能够促进服务供应商和医疗机构之间的数据全面分享。EHR包含医疗卫生服务中所产生的数据,例如诊断结果、治疗方案、处方、实验测试结果及放射诊疗结果。国际医疗卫生领域信息系统指标体系及交换协议(HL7)提供了电子医疗记录数据的交换、整合、共享、撤回等方面的基本标准。
▪ 医药研发:临床实验数据、基因数据。
▪ 病人行为和情绪数据。
▪ 医疗设备数据:家庭或医院的患者传感器数据。

大数据 在医疗卫生领域的发展趋势
现在有一种趋势是向着循证医学发展,即充分利用所有临床数据并能在临床和高级分析中对这些数据进行因子分解。抓取及收集关于某一个病人的所有信息能够为我们分析医疗服务协调性、分析基于效果的补偿体系、人口健康管理以及病人参与度和其他信息。

医疗卫生领域大数据应用案例分析
用 大数据分析 工具减少医疗诈骗、浪费和滥用
在美国医疗产业中,因欺诈、浪费和滥用而产生的成本是造成医疗费用节节上升的重要因素,但大数据分析能称为这一现象的变革者。医疗照护和医疗救助中心使用预测分析一年能够杜绝总额超过2.1亿的医疗保险欺诈。基于hadoop大数据平台的基础上,联合保健公司实现了向可预测的建模环境的转变。这个大数据平台能够以系统的、可重复的方式去甄别不正当的索赔申请,并能获得2200%的数据反馈。
辨别诈骗的关键是通过存储和可追溯的记录去分析历史赔偿记录中大量的非结构数据集,并利用机器学习的算法来甄别反常事物及模式。
医疗组织机构可以通过分析病人的纪录和账单来查明异常,例如短期内过度使用医疗服务,病人在不同地方的不同医院受到了医疗服务,或是同一个病人在多家机构得到了相同的处方。

医疗保护和医疗救助中心用预测分析来对某些特定的赔偿或医疗服务供应者进行风险评分,甄别计费模式并发现用传统方法难以查明的反常情况。以规则为基础的模式基本上能自动标示部分赔偿结果异常。而异常分析模式基本上是靠分析反常因素发现问题。预测分析模式是将某一赔偿案例与另外一个已被确认为诈骗的案例进行比较来发现可疑之处。而图表模式一般是依据关系网来分析,它认为一般存疑的医疗服务提供者总是与其他存在欺诈性的收费者保持紧密联系。
通过预测分析提高效果
不少积极的尝试,例如正在加速电子健康记录(Electronic Health Records,EHRs)的有效利用、病人信息的数量和细节,能够通过多种信息源组合、分析各种各样的结构化和非结构化的数据有助于提高诊断病人病状的准确性、根据病状匹配治疗方案以及预测病人患病或再患病的风险。
以电子健康记录(EHR)中的数据为来源的预测模型被应用于早起疾病的检测,并且还降低了一些疾病的死亡率,比如充血性心力衰竭(CHF)和败血症等疾病。降低充血性心力衰竭(Congestive Heart Failure ,CHF)和败血症等疾病的死亡率。CHF在医疗保健支出的占比最大,CHF越早治疗越好,这样能够避免花更多的钱治疗并发症。但是医生常常会忽略它的早期临床表现。来自于佐治亚理工学院的一个机器学习示例表明机器学习算法能够比医生从病人的图表中分析出更多的因素,同时通过增加额外的特征,机器学习算法能够有效提高模型区分CHF患者和非CHF患者的能力。
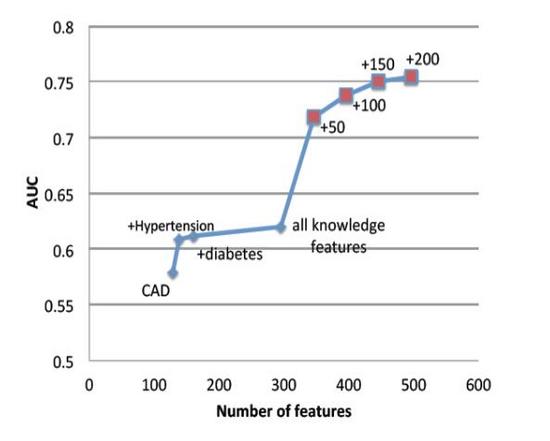
通过分析包含更多病患数据的大样本数据,预测模型和机器学习能发现之前未能发现的细微差别和模式。Optum实验室从EHRs中搜集30万病人的信息,为预测分析工具创建了一个庞大的数据库。这些工具将会帮助医生做出基于大数据信息的决策,从而改善病人的治疗。

实时监控病情
医疗机构正在通过持续性监控病人生命特征来提供更加具有主动性的治疗,各种监控数据能进行实时分析并及时发送警告给医疗服务提供者以便他们能及时了解病人病情的变化。通过机器学习算法进行实时分析能够帮助医生做出挽救性命的决策并且对一些病症进行有效干预。

医疗 大数据架构 :我们应该怎么做?规模化后又该如何做?
我们需要收集数据、处理数据、存储数据,并最终将数据用于分析,机器学习和数据表盘。

数据撷取:NFS
通过网络文件系统(NFS)协议可远程访问网络共享磁盘。启用NFS服务器后,可与客户共享目录和文件,让用户和程序像访问存储在本地的文件一样访问远程系统上的文件。
与只允许集群数据导入或批量导入的其它版本的Hadoop不同,MapR允许通过NFS直接挂载群集本身,让您的应用程序直接读取、写入数据。通过POSIX语义,该MapR文件系统允许直接修改文件和多个并发读取写入操作。挂装NFS的集群可实现对数据源的简单数据撷取,比如说从其他应用标准Linux命令、实用程序、应用程序和脚本的设备上撷取文件、图片等。

通过使用NFS可从MapR集群移出移入数据至更昂贵的存储空间。例如,您可以将处理过的热数据转移到关系数据库或数据仓库,您也可以将冷数据转移到成本更低的Hadoop存储中。
流数据撷取:KAFKA API
由于越来越多的医疗方案需要实时分析和动态数据,使用事件流撷取数据到系统中则将成为关键。 MapR流是一种新型的分布式通信系统,通过Apache Kafka 0.9 API可使得生产者和消费者之间实现实时交流事件动态。主题是信息的逻辑化集合,可依据其将事件分门别类。
主题分区域放置。主题将并行数据负载传遍多个服务器,这保证了更高的吞吐量和可扩展性。
读取后消息并不会从主题中删除,而且主题可以有多个不同的消费者,这使得抱有不同目的不同消费者处理可以处理同一消息。

批量处理
当快速相应时间不是核心要素时,就可采用数据批量处理。批量处理用于处理一段时间积累的数据集。例如白天收集EDI声明,晚上打包至文件夹中准备用于处理。
Apache Hive是一个用于数据仓储的开源Hadoop应用程序。它提供了一个便捷的方式在大量的非结构化数据之上建立框架,然后对这些数据进行类似SQL查询操作的批处理程序。
Apache的Spark是下一代分布式并行处理框架,可为机器学习、图形处理、SQL等提供一套丰富的API。 对于迭代算法,Spark处理速度要比MapReduce更快,因为Apache尽量将相关信息储存在储存器中,而MapReduce则更多地直接从盘中读取和写入。

流式数据处理
Spark Streaming是基于Spark的实时计算框架,其将流式计算分解成一系列短小的批处理作业。因此,你可以像编写批处理作业一样编写流作业。当然,处理大规模流式数据,除了Spark Streaming, Apache Flink 和 Apache Storm也是不错的选择。

NOSQL数据库存储
存储海量数据,我们需要一个既能满足快速写入又能满足大批量录入的数据库。MapR-DB应运而生,MapR-DB就是为了规模化写入而设计,因为事实上同时读取的数据也存储在一起。

有了MapR-DB, 数据可以通过关键域在数据集群之间完成自动分配,每个服务器对应一个子数据集的源。如果按行分组数据,无疑会加快数据读写速度。

MapR-DB有两个API:
▪ JSON API――用于存储文件模型
▪ HBase API――用于列数据模型(尤其是时间序列数据)

提供数据
终端应用,例如数据表盘、商业智能工具以及其他的应用,需要使用已处理好的数据。同时,这些数据可以再存回数据库,方便日后使用。
Apache Drill 支持无模式SQL查询引擎,因此能够实现海量数据的自助式数据探索。能够实现海量数据自助服务SQL查询。Drill有如下优点:
▪ Drill支持多种数据读取
▪ Drill进行了交互式应用方面的优化,可以在秒级别的时间查询PB级别数据及万亿条记录
▪ 数据分析师在使用Drill的时候,可以搭配一些例如Tableau的工具,就能够快速实现数据可视化。

以上我们讨论的架构组建,都能与mapr 融合数据平台在同一数据集群上运行。当然,整合Hadoop、Spark、实时数据库、全球性事件流及大规模企业级存储,还会带来以下好处:
▪ 维护一个数据集群,意味着更少的系统架构部署和管理,对系统安全、稳定性和性能方面的监控也减少了。这样极大程度上降低了硬件和运营成本。
▪ 生产者和消费者在同一集群,将会降低因在不同集群和应用程序间复制或移动数据而造成的延迟。

案例架构
Valence Health使用MapR融合数据平台来创建作为该公司主要数据储存地的数据湖。该公司产生3000条内部数据记录,涵盖45种不同类型,包括实验室测试数据、病人生命体征、处方、药品津贴、索赔和支出等,其中索赔来自医生和医院两方面。在过去,如果我们要从2000万条实验室记录中检索一条记录,将花费22个小时。而MapR只需要20分钟,并且其所消耗的硬件资源还会大大减少。

国立卫生研究院为了整合各研究院的数据集,也创建了一个数据湖。这样,所有的数据都集中在一个地方,更加方便数据共享和处理。
UnitedHealthcare IT部门采用Hadoop框架创建了一个平台。该平台上有各种工具,能够
分析诸如索赔、处方、治疗计划参与者、合同服务提供者及相关的索赔审议结果等信息。
医疗卫生服务的记录系统流
Liaison科技提出一个基于云的方案,帮助组织机构整合、管理、保护跨公司数据。针对医疗服务和生命科学产业,他们提供了一个纵向解决方案,该方案面临两个难题:符合HIPAA规定需要以及数据格式及呈现方式的推广。针对第一个问题,MapR将该规定的数据谱系流式化,数据流成为了一个记录系统――一个无穷尽而又不可随意更改的数据交换记录日志。

针对后一问题,我们通过一个例子来了解。一个病人的记录有可能被不同的用户,例如制药公司、医院、诊所、医生等以文件或图表形式呈现或以检索等方式使用。通过把即时数据变化通过数据流的形式处理成MapR-DB HBase、MapR-DB JSON文件、图表,并录入搜索数据库中。此外,通过应用MapR数据整合平台的服务,Liaison可以保护所有的数据,避免冗余数据和安全需求累积,而这是对备选方案的基本要求。
基因处理
Novartis团队采用Hadoop 和Apache Spark打造了一个工作流系统。这个系统为NGS(Next Generation Sequencing)研究整合、处理、分析各种类型的数据。

随着科技的发展,普通硬件无论是存储性能还是快速处理大数据的能力都大幅提升。随着通过捕获、共享、存储大量电子医疗服务数据和交易等技术的成熟,医疗服务行业正逐步变革,不断提高产出并降低花销。![]()



 |



 |



