一、概述
音频信号数字化之后所面临的一个问题是巨大的数据量,这为存储和传输带来了压力。例如,对于CD音质的数字音频,所用的采样频率为44.1kHz,量化精度为16bit;采用双声道立体声时,其数码率约为1.41Mbit/s;1秒的CD立体声信号需要约176.4KB的存储空间。因此,为了降低传输或存储的费用,就必须对数字音频信号进行编码压缩。到目前为止,音频信号经压缩后的数码率降低到32至256kbit/s,语音低至8kbit/s以下,个别甚至到2kbit/s。
|

为使编码后的音频信息可以被广泛地使用,在进行音频信息编码时需要采用标准的算法。因而,需要对音频编码进行标准化。
二、音频编码技术和应用
2.1音频信号
通常将人耳可以听到的频率在20Hz到20KHz的声波称为为音频信号。人的发音器官发出的声音频段在80Hz到3400Hz之间,人说话的信号频率在300到3000Hz,有的人将该频段的信号称为语音信号。在多媒体技术中,处理的主要是音频信号,它包括音乐、语音、风声、雨声、鸟叫声、机器声等。
表1 数字音频等级
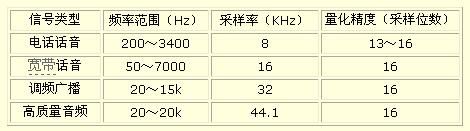
2.2音频编码技术
对数字音频信息的压缩主要是依据音频信息自身的相关性以及人耳对音频信息的听觉冗余度。音频信息在编码技术中通常分成两类来处理,分别是语音和音乐,各自采用的技术有差异。现代声码器的一个重要的课题是,如何把语音和音乐的编码融合起来。
语音编码技术又分为三类:波形编码、参数编码以及混合编码。
波形编码:波形编码是在时域上进行处理,力图使重建的语音波形保持原始语音信号的形状,它将语音信号作为一般的波形信号来处理,具有适应能力强、话音质量好等优点,缺点是压缩比偏低。该类编码的技术主要有非线性量化技术、时域自适应差分编码和量化技术。非线性量化技术利用语音信号小幅度出现的概率大而大幅度出现的概率小的特点,通过为小信号分配小的量化阶,为大信号分配大的量阶来减少总量化误差。我们最常用的G.711标准用的就是这个技术。自适应差分编码是利用过去的语音来预测当前的语音,只对它们的差进行编码,从而大大减少了编码数据的动态范围,节省了码率。自适应量化技术是根据量化数据的动态范围来动态调整量阶,使得量阶与量化数据相匹配。G.726标准中应用了这两项技术,G.722标准把语音分成高低两个子带,然后在每个子带中分别应用这两项技术。
参数编码:利用语音信息产生的数学模型,提取语音信号的特征参量,并按照模型参数重构音频信号。它只能收敛到模型约束的最好质量上,力图使重建语音信号具有尽可能高的可懂性,而重建信号的波形与原始语音信号的波形相比可能会有相当大的差别。这种编码技术的优点是压缩比高,但重建音频信号的质量较差,自然度低,适用于窄带信道的语音通讯,如军事通讯、航空通讯等。美国的军方标准LPC-10,就是从语音信号中提取出来反射系数、增益、基音周期、清/浊音标志等参数进行编码的。MPEG-4标准中的HVXC声码器用的也是参数编码技术,当它在无声信号片段时,激励信号与在CELP时相似,都是通过一个码本索引和通过幅度信息描述;在发声信号片段时则应用了谐波综合,它是将基音和谐音的正弦振荡按照传输的基频进行综合。
混合编码:将上述两种编码方法结合起来,采用混合编码的方法,可以在较低的数码率上得到较高的音质。它的基本原理是合成分析法,将综合滤波器引入编码器,与分析器相结合,在编码器中将激励输入综合滤波器产生与译码器端完全一致的合成语音,然后将合成语音与原始语音相比较(波形编码思想),根据均方误差最小原则,求得最佳的激励信号,然后把激励信号以及分析出来的综合滤波器编码送给解码端。这种得到综合滤波器和最佳激励的过程称为分析(得到语音参数);用激励和综合滤波器合成语音的过程称为综合;由此我们可以看出CELP编码把参数编码和波形编码的优点结合在了一起,使得用较低码率产生较好的音质成为可能。通过设计不同的码本和码本搜索技术,产生了很多编码标准,目前我们通讯中用到的大多数语音编码器都采用了混合编码技术。例如在互联网上的G.723.1和G.729标准,在GSM上的EFR、HR标准,在3GPP2上的EVRC、QCELP标准,在3GPP上的AMR-NB/WB标准等等。


