图3 模块的局部数据结构
经过优化的程序和常用的数据结构的大小可以放在L2中。所以按照上面的分析将L2配置为256KBSRAM,将程序代码段(.text)、变量初值表(.cint)、常量字符串(.const)、全局变量静态变量(.bss/.far)、堆栈段(.stack)等放入L2SRAM当中,全局堆(.sysmem用于动态存储器分配)置于外部存储器。表1总结了编码器所要用到的存储空间分配情况。
表1编码器存储空间的分配

其中整像素运动估计参考缓冲区包括亮度和色度。因为参考帧有两个,整像素运动估计参考缓冲区也有两个。分像素运动估计参考缓冲区也是两个:一个用来调入SKIP编码模式的预测值,一个用来做分像素运动估计。
3.3CPU与DMA并行性设计
I帧编码可以说是P帧编码的特例,如果P帧中不用运动估计的话,则与I帧编码流程相同。因此下面对于CPU与DMA的并行性的讨论只针对P帧。
我们要解决的问题是CPU什么时候发QDMA请求,命令DMA控制器将需要的数据调入内存中。而且这种调度方式要保证CPU发命令之后可以进行其它的计算,等CPU需要这些数据的时候,DMA已经将其调入内存中了。
为了解决这个问题需要了解编码器各个模块的运行时间,以及DMA调度数据到内存所需要的时间。通过在DM642上运行优化过的程序,一个参考帧情况下测得各部分占程序运行时间的比例大致如表2所示:
表2程序各部分运行时间所占比例
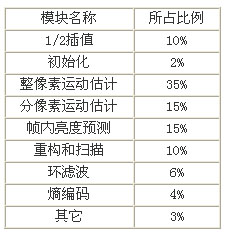
图4中由CPU指向DMA的箭头表示启动QDMA传输。每个DMA传输所用的时间相对于程序运行的时间比例是:传输原始像素占1%,传输SKIP和分像素运动估计参考区各占3%,传输整像素亮度和色度参考区共15%,传输环路滤波结果5%。整个DMA传输的时间大概占CPU计算时间的30%。通过这些数据可以看出,按照图4进行安排可以达到上面所述目标。

图4 CPU与DMA并行工作
只依靠上面这些方法进行优化,视频压缩还不能达到实时要求,还需要进行算法级优化,以及对编码器中各个模块进行程序代码级的优化。常通过采用内联函数、软件流水、线性汇编优化等方法,以及合理使用针对视频处理而设计的特殊指令集,充分利用DM642内部的并行计算单元,提高了程序的运行速度。由于篇幅有限,对这些优化方法本文不再重点论述。
4 .结论
结合AVS-M视频压缩处理流程的特点,本文完成了一个基于DM642平台的编码器的设计与实现。通过对编码流程的合理安排使得CPU能与DMA控制器并行工作,CPU不用等待数据,需要的数据已经被DMA调到内存中。实验表明通过系统级优化、程序级优化、汇编级优化、算法级优化等优化之后,基于这款视频服务器(实物图见图5),能达到2路CIF352x288格式实时视频压缩,以及音频实时编码、解码处理,且图像主观效果及音频效果良好。
本文创新点是:把具有自主知识产权的数字音视频编解码技术标准第七部分(AVS-M)应用于视频服务器的视频压缩,目前市场上还没有采用此压缩标准的产品,此产品具有极高得性价比,采用此压缩标准还可以避免产品产业化之后知识产权之争,具有很好的应用前景。

图5IMlab6421视频服务器实物图


