
当然真正的AI不仅仅是这三种类型,不过当下,我们花了大量时间在不断靠近这三个领域。现在让我们的生活、我们的世界更加好也就是机器学习和人工智能的最终目标。
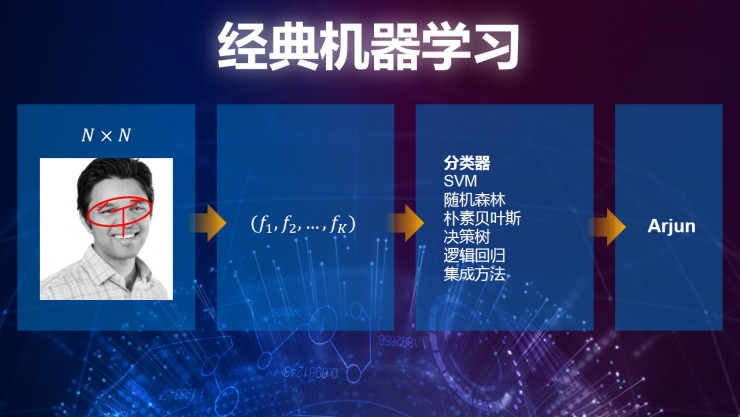
下面给大家举一个例子――非常传统经典的机器学习,我们在过去所学习到的,我们有一定的图片。大家可以看到这是我们其中的一个创始人,我们如何教会机器能够识别人的面孔,也就是说将名字和面孔连接在一起。按照传统方法来说,我要看一下他面部的特点,眼睛和眉毛的宽度和鼻子的长度,这些都是非常关键的辨识特点,通过软件辨识,作为图像的关键点,作为面部特点的函数。最后我们通过不同的分类器,不同的随机森林和集成方法,最终能够辨别出他的名字。我想人类或者是动物能够更好的辨别这个面孔,但是机器需要很多的学习过程,因为它们没有办法直接提取出这些特点。传统的机器学习就是以这种方式进行面部识别的。
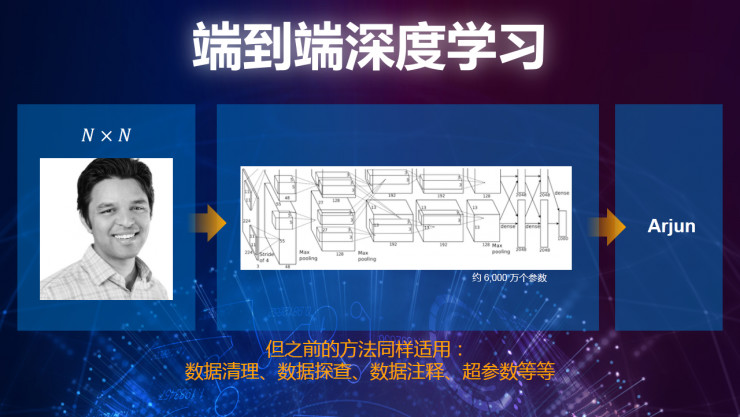
我们看一下深度学习,在过去几年当中有非常多的研究方面的突破,也就是说在数据层面提取出特征来进行学习。我们首先要了解特征是什么,这是我们数据的输出,这是数据的输入,告诉我在这个过程当中你提取出来的特征是什么。通过大量的计算能力,这也是为什么在过去花的时间,通过大量数据的学习可能要花几个月、几年的时间,因为之前这个计算的能力是非常受限的。

现在系统的发展更加先进,我们把它叫做端对端的深度学习,它有超过6000万个参数,这6000万个参数就代表着有6000万个不同的培训点,同时这个数据,可以看到它有自己的一些范式,我们可以将这个问题变得简单化。但是在这边我们需要注意的一点,这一点非常重要,我们应该有非常好的数据,非常好的标记,与此同时能够对我们输入的信息作出正确的定义。
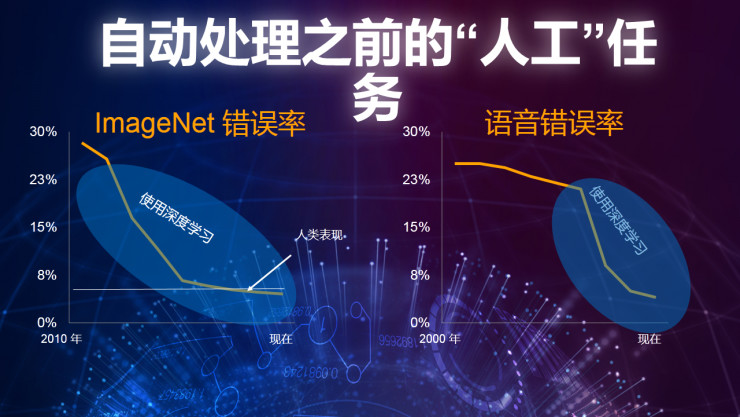
所以在过去几年间,信息界发生的一个很大的变化是机器学习正在处理之前人工处理的一些内容,比如说之前有一些自然的图像,我们有1000多个类别,当时的想法是,把这些图像按类别进行分类,看起来非常简单,不知道在座各位有没有做过这样一些工作,这些工作正确率在80%左右,正确率不是特别差,如果看计算机进行分类的话,错误率也没有低很多,如果我们对所有机器进行培训的话,这些受过训练的机器可以达到更高的分类精度。
之后我们为了解决错误率的问题,去应用了神经网络,你会看到在应用神经网络之后语音错误率以及ImageNet错误率得到了进一步下降。我们在这边看到了人类的表现,人类的错误率,其实我们所做的是研究这些错误,我们大概有5%左右的错误率,过去几年间,真正让机器能够打败人类或者打败其他智能的动物还需要几年的时间,但是我们确实已经见证多了一些重大的进步,大家已经有了智能手机,我们说到这些智能系统的时候,我们知道这些智能手机的智能系统是非常好的,可以在大部分情况下帮我们作出正确的选择,因为我们在它上面加入了神经网络,因此我们可以帮他们的正确率得到提高。在Nervana我们也在整个平台上应用了各种各样不同的数据,我们用了自然语言加工,我们用了很多时间序列、金融数据等等,这些都是朝着同样一个方向发展的。
展望机器学习的未来




 |





 |



